
기계가 인간을 뛰어넘을 수 있을까. 또 인간은 기계의 도전을 막아낼 수 있을까. 기계와 인간의 역사적인 대결이 예고됐다. 바둑 챔피언 이세돌 9단과 구글 딥마인드(Google DeepMind)의 인공지능 바둑 프로그램 ‘알파고(AlphaGo)’의 대국이 오는 3월 열린다. 경기의 결과 앞에 인류의 역사는 두 개의 갈림길과 만난다. 기계가 인간을 뛰어넘어 새로운 ‘생각하는 존재’로 기록되거나. 인간을 뛰어넘는 기계의 등장이 지금이 아닌 미래로 잠시 유보되거나. 과학자뿐만 아니라 전 세계인들의 눈과 귀가 3월 한국의 서울을 주목하고 있다.

바둑 챔피언 이세돌 9단과 구글 딥마인드의 인공지능 바둑 프로그램 ‘알파고’의 대국이 오는 3월 한국에서 열린다. <출처: 네이처 유튜브 동영상>
컴퓨터엔 너무 어려웠던 바둑의 세계
이세돌 9단과 알파고의 대결은 알파고의 앞선 승리 덕분에 이뤄지게 됐다. 알파고는 구글이 소유한 인공지능 기술 개발업체 딥마인드가 창조해낸 인공지능 바둑 시스템이다. 딥마인드는 2010년 영국에서 설립됐다. 구글이 딥마인드를 인수한 시점은 2014년 1월이다. 딥마인드가 구글에 인수된 이후인 2015년 10월에는 유럽의 바둑 챔피언 판 후이(Fan Hui) 2단을 상대로 공식 대국에서 승리했다. 5번 진행된 대국 모두 알파고의 승리로 끝났다. 사람이 만든 인공지능 시스템이 프로 바둑 기사를 능가하는 실력을 갖추게 됐음을 현격한 실력 차이로 입증한 셈이다.
지금까지 바둑은 컴퓨터 인공지능이 도전하기엔 너무 어려운 게임이었다. 체스는 이미 지난 1997년 인간이 컴퓨터에 정복당한 영역 중 하나다. IBM이 개발한 슈퍼컴퓨터 ‘딥블루(Deep Blue)’가 체스 세계 챔피언 가리 카스파로프를 꺾은 것이 기준점이다. 인공지능이 체스로 인간을 정복한 이후 20여년이 지나는 동안에도 바둑은 여전히 컴퓨터에 미지의 영역으로 남아 있었다.

체스와 달리 바둑이 인공지능의 도전 과제로 남아있을 수 있었던 까닭은 바로 복잡성이다. 바둑의 규칙은 매우 간단하다. 바둑판 위 흰 돌과 검은 돌을 번갈아 놓으며 상대편의 돌을 들어내거나 공간을 둘러싸 ‘집’을 만드는 것이 목표다. 하지만 컴퓨터가 고려해야 하는 경우의 수는 체스와 비교해 기하급수적으로 늘어난다. 체스는 말을 움직이는 방법이 정해져 있지만, 바둑은 자유롭게 돌을 놓는 방식이기 때문이다. 또, 체스와 비교해 바둑은 게임의 판이 더 크다. 바둑 경기의 경우의 수는 10의 170 제곱에 이른다. 이를 숫자로 풀면 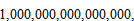
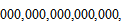
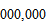 이나 될 정도로 막대한 숫자다. 이는 우주에 있는 원자의 수보다 큰 숫자다. 체스와 비교할 때 경우의 수가 10의 100 제곱 이상 많은 것이기도 하다.
이나 될 정도로 막대한 숫자다. 이는 우주에 있는 원자의 수보다 큰 숫자다. 체스와 비교할 때 경우의 수가 10의 100 제곱 이상 많은 것이기도 하다.
알파고는 프로 바둑기사를 어떻게 이겼을까
딥마인드는 알파고 시스템을 구축하는 과정에서 ‘트리탐색(Tree Search)’ 기술을 이용하는 대신 ‘몬테카를로트리탐색(MCTS)’ 기술과 ‘심층신경망(Deep Neural Network)’ 기술을 결합해 활용하도록 설계했다. 몬테카를로트리서치는 선택지 중 가장 유리한 선택을 하도록 돕는 알고리즘이다. 예를 들어 알파고가 검은 돌로 대국을 벌인다고 가정할 때, 흰 돌이 어디에 위치하느냐에 따라 검은 돌을 두는 알파고의 선택이 달라지도록 한다는 의미다. 이 같은 최적의 선택이 반복될수록 대국은 유리하게 풀린다.
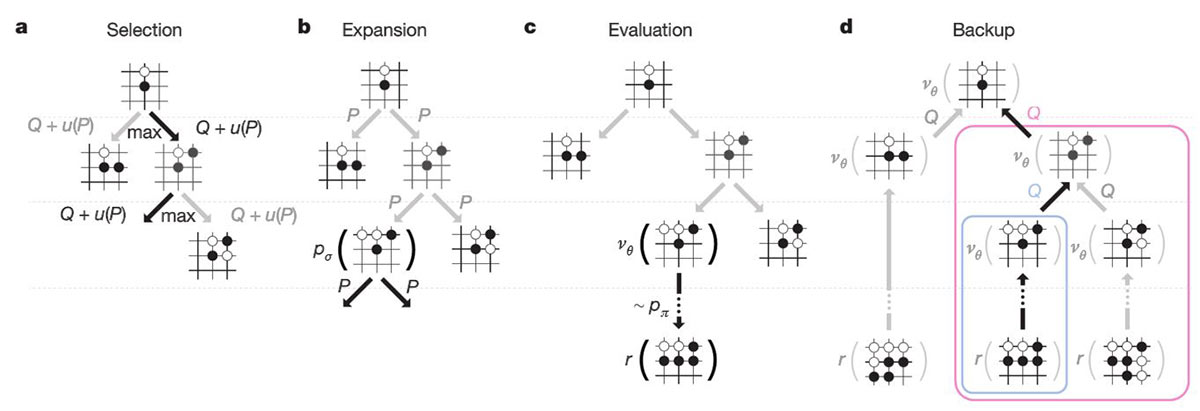
몬테카를로트리서치 알고리즘 <출처: Mastering the game of Go with deep neural networks and tree search - Nature, 2016>
구체적으로 알파고가 바둑돌을 놓을 위치를 정하는 알고리즘은 ‘정책망(policy network)’이라는 이름이 붙여진 신경망과 ‘가치망(value network)’이라고 부르는 또 다른 신경망의 결합에 의해 이루어진다. 정책망은 다음에 돌을 어디에 둘지 선택하는 알고리즘이고, 가치망은 승자를 예측하는 역할을 한다. 말하자면, 알파고의 바둑 대국은 머신러닝으로 훈련된 정책망과 가치망의 결합이 몬테카를로트리리서치 알고리즘을 통해 발현되는 것이다.
알파고의 머신러닝 훈련 첫 단계는 ‘정책망 지도학습(Supervised learning of policy networks)’이다. 바둑기사가 그러하듯 바둑돌의 다음 위치를 예측하도록 훈련하는 과정이다. 딥마인드는 총 13개의 레이어로 구성된 정책망을 디자인하고, KGS 바둑 서버에 등록된 3천만개의 바둑돌 위치 정보를 바탕으로 훈련시켰다. 이 같은 과정을 통해 과거 44% 수준에 머물던 인공지능의 예측 확률을 57%까지 끌어올릴 수 있었다는 게 딥마인드의 설명이다.

알파고 훈련의 두 번째 단계는 ‘정책망 강화학습(Reinforcement learning of policy networks)’이다. 말 그대로 강화학습을 통해 정책망의 성능을 개선하는 단계다. 딥마인드는 현재의 정책망과 무작위로 선택된 정책망 사이의 무수한 반복 대결을 통해 알파고를 학습하도록 했다. 현재의 플레이어 관점에서 시스템이 대국에서 이기면 보상을 받고(+1), 지면 보상을 잃는(-1) 방식으로 정책망 강화학습이 진행됐다. 딥마인드는 이 같은 과정을 통해 강화학습 정책망이 강화학습 이전의 지도학습 정책망과 비교해 80% 더 많은 대국에서 이길 수 있게 됐다고 설명한다.
마지막 단계는 ‘가치망 강화학습(Reinforcement learning of value networks)’이다. 바둑돌의 위치 평가를 바탕으로 결과를 예측하는 것을 강화하는 단계다. 3천만개가 넘는 위치 정보를 바탕으로 ‘셀프 대국’을 벌여 가치망의 분석 능력을 업그레이드했다.

알파고 “준비는 끝났다”
딥마인드는 다양한 바둑 소프트웨어와 대국을 벌여 꾸준히 알파고의 실력을 검증했다. 현재 가장 강력하다고 알려진 상업용 바둑 소프트웨어 ‘크레이지 스톤(Crazystone)’과 ‘젠(Zen)’을 포함해 오픈소스 바둑 프로그램 ‘파치(Pachi)’와 '푸에고(Fuego)' 등이 알파고의 연습 대국 토너먼트 상대가 됐다.
결과가 놀랍다. 딥마인드의 알파고는 총 495회 바둑 소프트웨어와 대국을 벌여 딱 한 번을 패배하고 494개 대국에서 승리를 거머쥐었다. 승률로 따지면 99.8% 수준이다. 알파고가 기존의 다른 바둑 소프트웨어와 비교해 몇 단이나 높은 실력을 갖추고 있다는 게 딥마인드의 자체 평가다.

판 후이 2단과 알파고의 대결. 알파고는 5판 모두 승리했다. <출처: 딥마인드 유튜브 동영상>
셀프 대국을 포함한 알파고의 이 같은 반복 훈련은 2015년 10월5일부터 9일까지 열린 판 후이 2단과의 대국에서 전 대국 승리라는 최초이자 기념비적인 승리를 거머쥐는 데 주효하게 작용했다. 사람이 1년에 1천번 바둑을 둔다고 가정할 때, 1년에 해당하는 횟수의 대국을 지금도 치르는 중이다.
이제 남은 것은 지난 10여년 동안 바둑 최강자 자리를 지켜 온 이세돌 9단과의 승부다. 이세돌 9단과 알파고의 대결 역시 5판으로 이루어진다. 이세돌 9단의 자신감은 대단하다. 이세돌 9단의 말처럼 “3분에서 5분 이하로 고민”했을 정도로 이세돌 9단은 승리를 자신하고 있다. 12억원 상금을 건 이세돌 9단과 알파고의 대국은 인공지능이 인류의 지능에 어느 정도 수준까지 접근했는지를 가늠할 지적 축제이자, 컴퓨터에 대항하는 인간의 자존심을 건 승부가 됐다. 알파고와 이세돌 9단의 대국은 3월9일부터 15일까지 서울에서 열린다.
